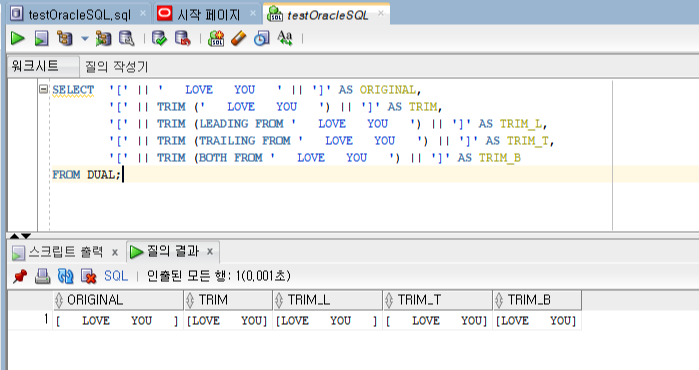
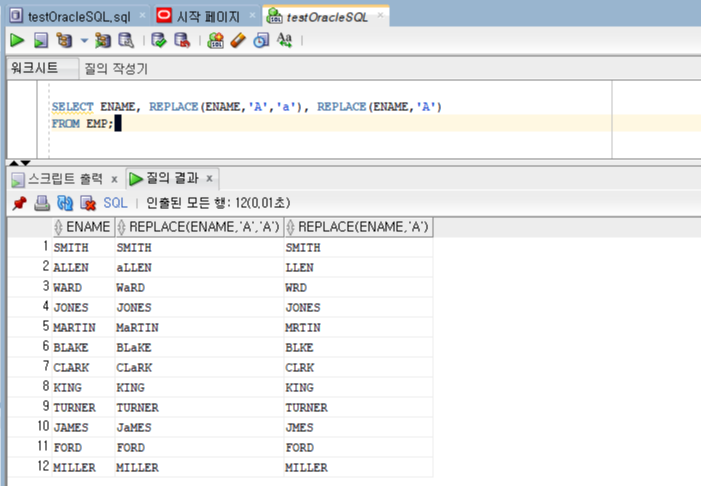
삭제 옵션에는 왼쪽 글자를 지우는 LEADING, 오른쪽 글자를 지우는 TRAILING, 양쪽 글자를 지우는 BOTH 가 있이며, 생략시에는 양쪽 값이 모두 삭제됩니다.
이때, 삭제할 문자는 필수가 아니며, 삭제할 문자를 지정하지 않으면 공백을 지웁니다.
SELECT '[' || ' LOVE YOU ' || ']' AS ORIGINAL, '[' || TRIM (' LOVE YOU ') || ']' AS TRIM, '[' || TRIM (LEADING FROM ' LOVE YOU ') || ']' AS TRIM_L, '[' || TRIM (TRAILING FROM ' LOVE YOU ') || ']' AS TRIM_T, '[' || TRIM (BOTH FROM ' LOVE YOU ') || ']' AS TRIM_B FROM DUAL;
이번에는 삭제할 문자열이 있는 경우를 살펴 봅시다.
SELECT '[' || '***LOVE***YOU***' || ']' AS ORIGINAL, '[' || TRIM ('*' FROM '***LOVE***YOU***') || ']' AS TRIM, '[' || TRIM (LEADING '*' FROM '***LOVE***YOU***') || ']' AS TRIM_L, '[' || TRIM (TRAILING '*' FROM '***LOVE***YOU***') || ']' AS TRIM_T, '[' || TRIM (BOTH '*' FROM '***LOVE***YOU***') || ']' AS TRIM_B FROM DUAL;
2. LTRIM, RTRIM 함수
TRIM 함수 이외에 LTRIM, RTRIM 함수를 사용에 대한 예제도 살펴 봅시다.
LTRIM( 원본 문자열 데이터, [삭제할 문자 또는 문자열] ) RTRIM(원본 문자열 데이터, [삭제할 문자 또는 문자열] )
LTRIM, RTRIM 함수는 각각 왼쪽, 오른쪽의 지정 문자 또는 문자열을 삭제할 때 사용합니다. 삭제할 문자 또는 문자열을 지정하지 않으면 공백 문자를 삭제합니다.
SELECT '[' || ' LOVE YOU ' || ']' AS ORIGINAL, '[' || TRIM (' LOVE YOU ') || ']' AS TRIM, '[' || LTRIM (' LOVE YOU ') || ']' AS LTRIM, '[' || RTRIM (' LOVE YOU ') || ']' AS RTRIM FROM DUAL;
공백이 아닌 문자열이 있는 경우를 예제로 살펴 봅시다.
SELECT '[' || '*_*LOVE*_*YOU*_*' || ']' AS ORIGINAL, '[' || TRIM ('*_*LOVE*_*YOU*_*') || ']' AS TRIM, '[' || LTRIM ('*_*LOVE*_*YOU*_*', '*_') || ']' AS LTRIM, '[' || RTRIM ('*_*LOVE*_*YOU*_*', '*_') || ']' AS RTRIM FROM DUAL;
실무에서는 데이터를 저장할때 저장할 데이터 앞이나, 끝에 의미 없는 공백을 제거하고 저장 한다거나, Login시 사용자의 실수로 입력된 공백이 있을 수 있어 이를 제거하고 비교할때 사용 됩니다.
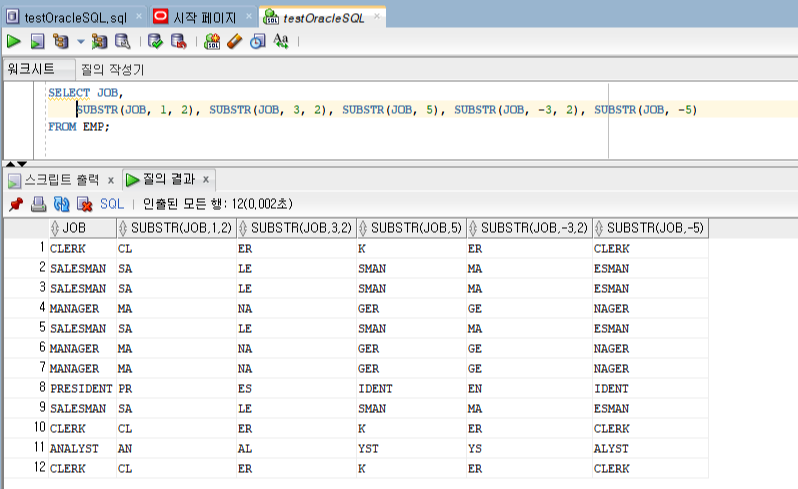
단어에서 시작하는 첫 알파벳만 알고 싶거SUBSTR나, 전화번호에서 마지막 네자리 숫자만 알고 싶을때는 문자열 일부를 추출하는 함수인 SUBSTR를 사용합니다.
함수
설명
SUBSTR(문자열 데이터, 시작위치, [추출길이] )
- 문자열 데이터의 시작 위치부터 추출 길이 만큼의 문자열을 출력합니다. - 시작위치가 음수인경우 문자열의 끝에서 부터 역산하여 위치를 찾아 해당 위치부터 추출 길이 만큼의 문자열을 출력합니다. - 추출길이가 생략된 경우 문자열의 시작위치 부터 끝까지를 출력합니다. 이때, 시작위치가 음수이면 문자열의 끝에서 부터 역산한 위치부터 끝까지의 문자열을 출력합니다.
SELECT ENAME,UPPER(ENAME), LOWER(ENAME), INITCAP(ENAME) FROM EMP;
해당 함수들은 문서의 비교나 특정 문자열을 찾는 경우, 해당 문자가 대문자로 쓰여 있던, 소문자로 쓰였있던, 섞어서 쓰여 있던 상관없이 검색이 가능합니다. 즉 내가 'Oracle' 이라는 단어를 검색하고 싶은데, 문서에는 "oracle", "ORACLE", "OrAcLe"와 같은 형식으로 쓰여 있는 경우 일반검색으로는 찾을 수 없지만, 문자를 모두 대문자나, 소문자로 치환하면 비교하여 찾는 것이 가능합니다.
자료 검색의 예로 이름이 'TH'로 끝나는 직원을 찾는 쿼리를 만들어 봅시다. (LIKE 연산자에 대해 궁금하신 부분은 'SQL 연산자 - LIKE 연산자' 부분을 참고하시면 됩니다.)
SELECT * FROM EMP WHEREUPPER(ENAME) LIKE UPPER('%th');